There have been a number of well written pieces in recent days about emerging tech-stacks for AI (specially Gen AI) and how organizations can start thinking about setting-up and testing AI models in their workflows (e.g. Sequoia, A16z). While these articles are informative, in order to build a deeper understanding of how ‘AI for Science’ could advance, we also need to understand the EXISTING tech-stack that currently supports the Science system (as discussed in Edition 1). So below I present some thoughts on the “Science Stack”.
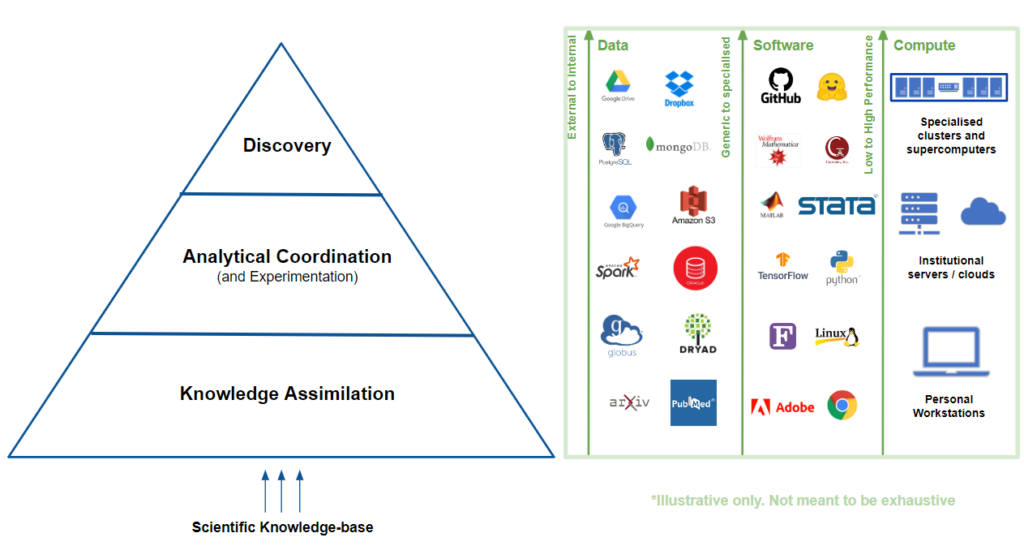
In the research workflow, three key elements—data, software, and computing—undergo significant transformations as projects transition from knowledge assimilation to Discovery. Initially, data is primarily sourced externally, from academic journals and existing databases. However, as the research progresses, there is an increasing reliance on specialized, internally-generated and experimental datasets. The modality of the data also becomes complex (think gene sequences, medical images, density function distributions, fMRI Voxels) and it becomes necessary to stitch together data from different sources.
Similarly, the software requirements evolve from using generic, off-the-shelf tools to custom-developed, open source, domain-specific applications. Scientists are tinkerers (it’s their job) and out of this tinkering has emerged a rich and vast ecosystem of repositories and recipes through which new approaches are devised and shared. And while there’s a lot of “technical debt” that has accumulated in the stack as a result of this decentralized exploration, its a true testament to the open nature of Science that anyone can get access to these tools and use them for their research.
And finally, In the realm of compute, projects typically start with basic computing resources (think laptop) but eventually demand high-performance computing (HPC) capabilities for data-intensive tasks and complex simulations. The needs are met through the collaborative efforts of national funding agencies, academic research institutions and the growing cadre of campus cyberinfrastructure specialists(see CaRCC, AskCI) which between them have created a thriving ecosystem of specialized hardware and tools to manage them
These trends are not coincidental but rather indicative of the evolving requirements of sophisticated research projects. The shift from external to internally-generated data often necessitates a corresponding shift to more specialized software and high-performance computing resources.
This interconnected escalation across data, software, and computing resources is the crucible through which existing knowledge must go through for a valid Discovery to come into existence.
Repeatable Research Containers (RRCs)
Any serious attempt to infuse AI in the Science system will have to take account of this diverse, fragmented and dynamic stack. While in an enterprise setting (where use cases are well-defined and infrastructure is monolithic) it’s easy to build once and scale. In Science, we will have to build for interoperability, portability and repeatability — and that’s why we need to think of AI infused Repeatable Research Containers. More on this in the next edition of AI4Science.
Some fun reading till then (some of these might be behind paywall) :
Scientific Containers –
Kurtzer, Gregory M. et al. “Singularity: Scientific containers for mobility of compute.”
Piraghaj, Sareh Fotuhi et al. “ContainerCloudSim: An environment for modeling and simulation of containers in cloud data centers.” Software: Practice and Experience
Tools for building containers –